
There exists a phenomenon known as “Agent Mysticism”: you have clearly outlined the task background, broken down the process, included common pitfalls, API usage, sample code, and even written a lengthy Skill document. Yet, when a similar task arises, the model may still make the same mistakes.
This approach shares a common premise: Experience stored, recalled, and fed back to the model can lead to improvements.
Delving into this phenomenon reveals an interesting, useful, yet “counterintuitive” issue: Comprehensive detailed documentation does not equate to high-quality control objects.
The industry has fundamentally misunderstood Skills here. Many treat Skills as the endpoint of intelligent reuse, overlooking that models do not “read” a document; instead, they seek the next strategy within limited reasoning budgets, identifying which actions to avoid and which constraints to prioritize.
For human engineers, completeness means security and standards; however, for models, completeness often dilutes signals, diminishes focus, and buries control under background material. In other words, the strength of Skills is precisely built on their service to human understanding, rather than serving the model’s decision-making in the current task.
Recently, the EvoMap team (Infinite Evolution Lab × Tsinghua University) conducted systematic research on this issue, proposing a memorable new concept: Gene. Inspired by biology, a gene is a DNA segment encoding proteins, derived from shared memories and experiences over centuries. The gene of an agent is a verifiable, reusable knowledge asset solidified through the GEP protocol.

- Paper Title: From Procedural Skills to Strategy Genes: Towards Experience-Driven Test-Time Evolution
- Authors: Junjie Wang, Yiming Ren, Haoyang Zhang
- Institution: Infinite Evolution Lab (EvoMap) × Tsinghua University
- arXiv: https://arxiv.org/abs/2604.15097
- Evolver: https://github.com/EvoMap/evolver
- CritPt Task Reproduction Repository: https://github.com/EvoMap/critpt-openclaw-reproducible-70

The paper demonstrates through 4,590 controlled experiments in 45 scientific coding scenarios and end-to-end validation on the CritPt benchmark that:
When the same underlying experience is injected into the model separately, the complete Skill package performs worse than the no-guidance baseline, while the much shorter Gene object consistently outperforms it.
This preference is not limited to the moment of “writing a Prompt”; it extends to the design principles of “how the Agent continuously evolves during testing.” Often, what determines whether an Agent is intelligent is not “how much experience you stored,” but rather “what form the experience takes when it returns to the model.”
What does this inspire? Today, when the industry discusses Agent optimization, the keywords are always: stronger base models, longer contexts, more advanced RAG, and more complex memory systems. However, Gene reveals that the key to experience reuse is not to provide the model with more substantive prompts but to create a compact, controllable, and sustainably evolving object from experience. This aspect has been largely overlooked in the entire Agent community.
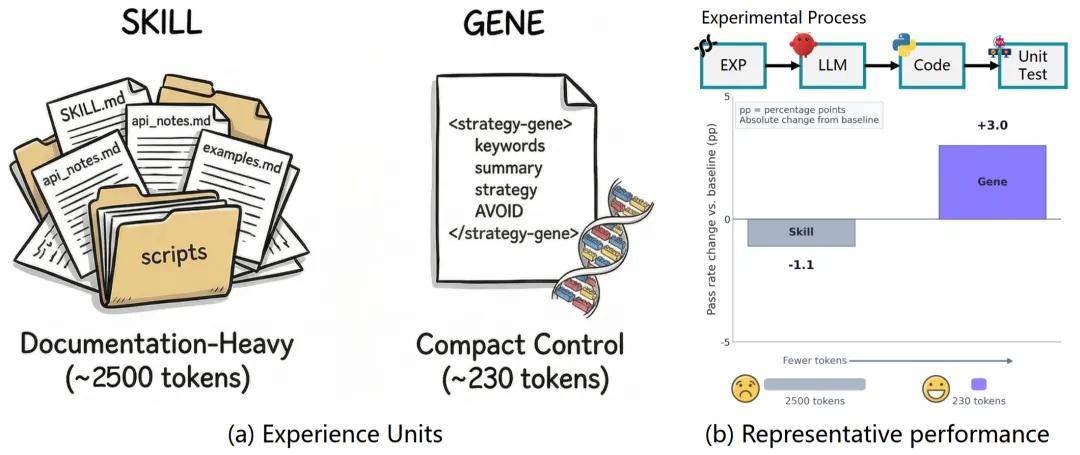
What is Gene?
The EvoMap team found that experience objects for the model should be designed based on “control density” rather than “document completeness.”
However, the team did not stop at this observation. After solidifying the phenomenon through 4,590 controlled experiments, they defined a replicable, mutable, and inheritable solution strategy, where Gene is a complete object layer within a three-layer framework:
Gene: Contains keywords + summary + strategy + AVOID four types of signals, which can be directly injected as test-time control snippets;
It serves as a reusable evolution strategy template for Agents. It defines “under what circumstances, what actions to take, and what constraints to follow”—equivalent to encoding prior knowledge.
A complete Gene includes fields such as signals, strategy, constraints, validation, and a unique asset_id.
Under extremely short token limitations, it possesses high control density, clarifying the trigger signals for the model, which “supports substring matching, regular expressions, and multilingual aliases,” ordered executable steps with execution validation and safety boundaries that “limit the scope of changes and prohibit touching certain paths,” and content-addressable hashes based on SHA-256, making it tamper-proof.
Capsule: Verified task-level execution paths + audit records;
Event: Immutable evolution logs.
These three components are interconnected through a six-stage loop, forming the GEP (Gene Evolution Protocol):

For details, see:
https://evomap.ai/wiki/16-gep-protocol
In simple terms, the entire operation process is as follows:
- First, distill past failures, successes, and repair paths into Gene (not writing documentation, but writing traceable control signals);
- When a new task arrives, Scan the task context → match the most relevant Gene → inject as System Instruction;
- After execution, write the result back as an Event, triggering validation/mutation/solidification of the Gene—allowing the Gene pool itself to continuously evolve without updating base model parameters.
How Gene “overcomes” Skill
All data comes from the same experimental pipeline: using fixed models Gemini 3.1 Pro Preview (Pro) and Gemini 3.1 Flash Lite Preview (Flash), executing in a sandbox + checkpoint pass rate as metrics, with temperature T=0.05 and maximum output of 16,384 tokens.
Skill loses to Gene, not in quality, but in form.
The paper first makes the most direct comparison: the same underlying experience is packaged into a Skill package of ~2,500 tokens and a Gene object of ~230 tokens.
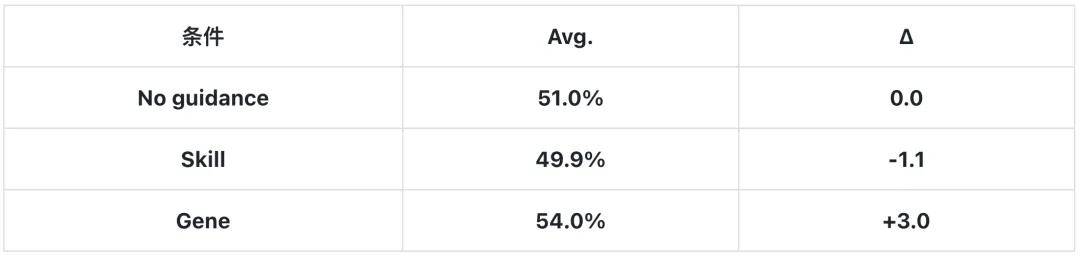
The complete Skill package averages 1.1pp below the no-guidance baseline across both models, while the shorter Gene outperforms by 3.0pp. Notably, Skill does not perform uniformly poorly; it shows improvement on the weaker model Flash (41.8→49.0) but severely drags down performance on the stronger model Pro (60.1→50.7)—long Skills directly suppress Pro’s inherent capabilities.
“Procedural skill” refers to the most common type of document-style experience package today. It typically includes: overview, workflow, pitfalls, error handling, API notes, examples, scripts, and experiments reveal which sections are effective:
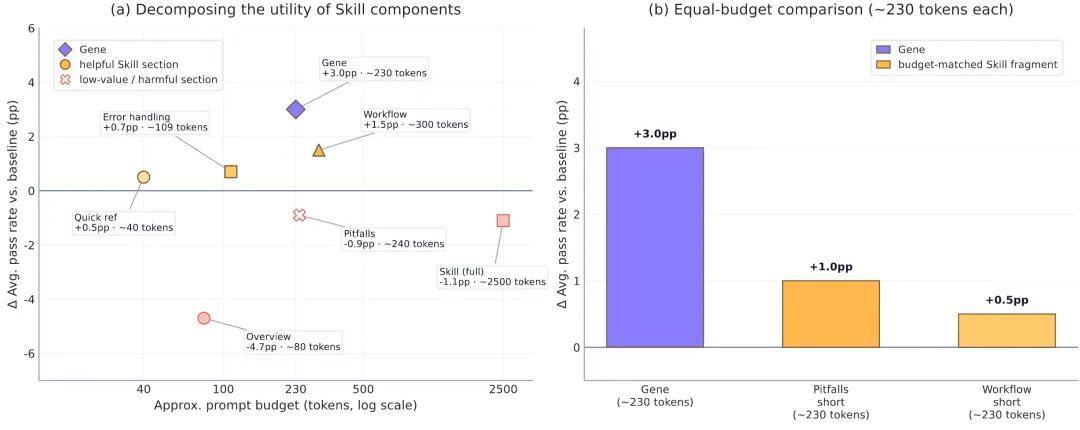
Only the Workflow section is genuinely effective, while the Overview contributes the largest negative impact. The useful signals in Skills are sparse, concentrated in a small section of procedural content, while the remaining extensive materials that serve human readability dilute or even contaminate control signals.
Skill loses to Gene, not in knowledge quantity or information density, but in the choice of controlled objects.
Stuffing human-readable content into the model’s execution budget becomes control noise.
Gene is not just a shorter prompt; it is a differently shaped object. What determines model behavior is the control structure, not the number of tokens; the strategy layer cannot be omitted.
In the paper’s perturbation experiments, the most counterintuitive finding was that a stale_paradigm Gene written with outdated algorithm paradigms scored 56.6%, higher than the clean Gene’s 54.0%; however, switching algorithms dropped to 48.8%, and switching domains to 49.4%—the conditions for losing points were adjacent.
These two results together complete the picture: The effective condition for Gene is “maintaining the task-relevant control framework,” rather than “being the newest.” Outdated methods can still be effective as long as the framework is correct; new methods can drag down performance if the framework is wrong. This comparison also hints at Gene’s robustness boundary: structurally tolerant but semantically selective.
The optimal form for summarizing failures is not logs but distilled warnings.
Everyone working on Agent systems faces a question: how should failures be stored?
Long trajectories? Reflection summaries? Error logs?
The EvoMap team focused on the critical question: If engineering budgets are limited, what form should failures take when returning to the model?
The paper ran two sets of controls.
Control One: Storing failures in different carriers
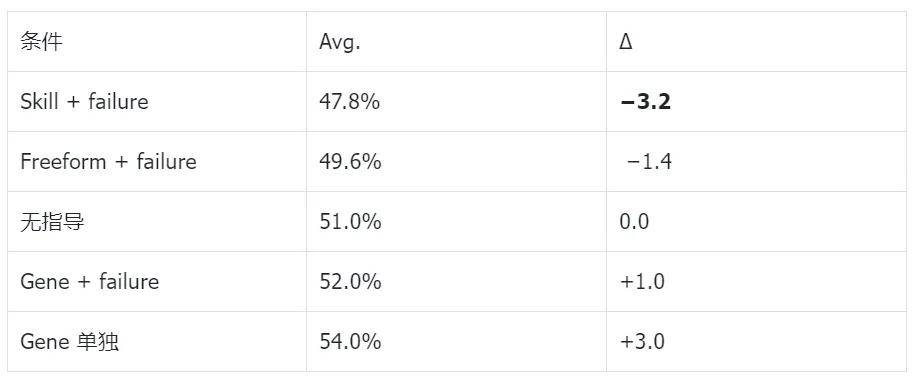
Stuffing failures into Skills or free text all fell below the no-guidance baseline.
Gene was the only positive contributor—however, even then, Gene + failure was still less effective than Gene alone (54.0 → 52.0).
Adding failures back diluted Gene.
Control Two: How failures and strategies are mixed
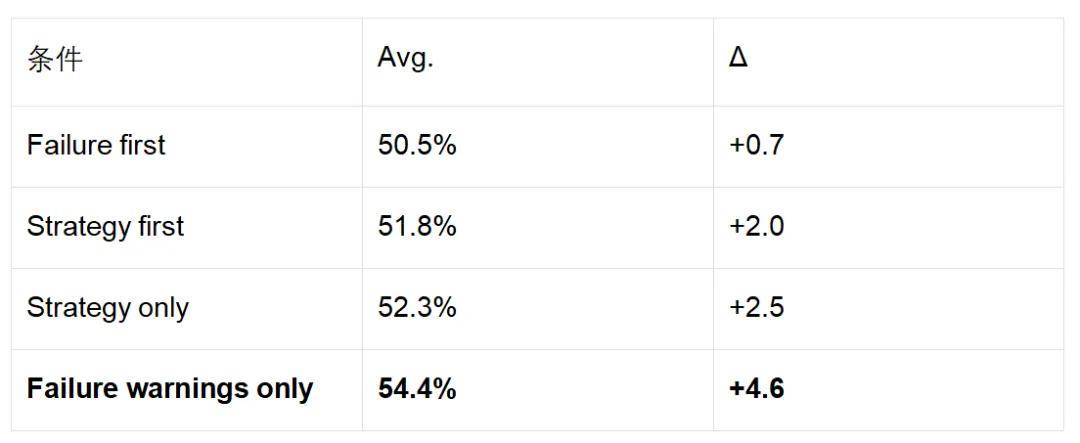
The strongest combination was neither a “failure + strategy” mixture nor “strategy only,” but rather failure warnings only—distilling failures into independent “AVOID xxx” statements proved stronger than retaining the strategy itself.
In other words, the truly useful failure experiences for Agents should not take the form of “logs” but rather like this (real AVOID from the paper’s UV-vis spectral scenario):
- AVOID treating min_distance as wavelength values passed to scipy.signal.find_peaks; convert to sample point units first.
- AVOID reporting FWHM directly from peak_widths outputs; convert back to wavelength units first.
The underlying principle is clear: The accumulation of failure experiences should be selective compression, not additive stacking.
What does Gene look like? A minimal verifiable artifact.
At this point, it’s worth looking at what a real Gene looks like. Below is an injection example from the paper’s UV-vis scenario:
Domain keywords: uv-vis, peak detection, FWHM, unit conversion
Summary: Detect peaks and compute wavelength-domain peak properties correctly
Strategy:
- Detect peaks with prominence-based criteria.
- Convert min_distance into sample-index units before peak detection.
- AVOID: Report FWHM only after converting peak_widths outputs back to wavelength units.
About 230 tokens, 5 fields. Its counterpart is the same experience packaged as a Skill:
About 2,500 tokens, including overview, workflow, pitfalls, API notes, examples, scripts, etc., resembling a README.
Both were tested using the same system instruction injection slot and the same set of sandbox evaluation scripts—meaning the control conditions were entirely consistent, with the only difference being “the form of the content injected.”
The GEP protocol further standardizes this original Gene into verifiable objects with fields such as id/schema_version/signals_match/strategy/constraints/validation/asset_id—aiming to make it matchable, replaceable, modifiable, and combinable, rather than just a well-formatted prompt.
The rules at the protocol level have changed.
**The most remarkable aspect of Gene is that it does not limit the “experience object” to a clever prompt technique but directly addresses the protocol layer.
During the control (Inference) phase, the logic is very smooth: using the same scientific coding question, replacing the ~2,500 token Skill package with a ~230 token Gene control snippet, the model computes more accurately.
However, regarding the protocol layer, the EvoMap team presents a more fundamental judgment: When experience objects are exchanged between multiple Agents, they must be objects, not just a document.
Why? Because without a protocol, Gene remains just a prompt segment—unstable boundaries, incomparable fields, and cannot accumulate. Once protocolized, Gene transforms from a “prompt fragment” into matchable, replaceable, modifiable, and combinable objects that can be continuously revised, audited, and used consistently across multiple Agents.
GEP is not about format details but about elevating Gene from a test-time control object to a persistent strategy optimization interface.
Experimental Results: CritPt Ranking’s “Freemium” Intelligent Dark Horse
To provide data, the EvoMap team directly applied Evolver to the CritPt benchmark for end-to-end results.
CritPt is dynamic, strictly simulating the data set of real physical research processes. Benchmark website: https://critpt.com/
Evolver is a complete system of “base model + Gene pool + evolution engine + toolchain”.
(with OpenClaw as the host runtime, Evolver as the evolution engine, and Gene/GEP as the object and protocol layer); the recently popular Hermes Agent has also somewhat “borrowed” from Evolver’s design philosophy.
The full reproduction answers for Benchmark70 tasks can be found at (https://github.com/EvoMap/critpt-openclaw-reproducible-70).
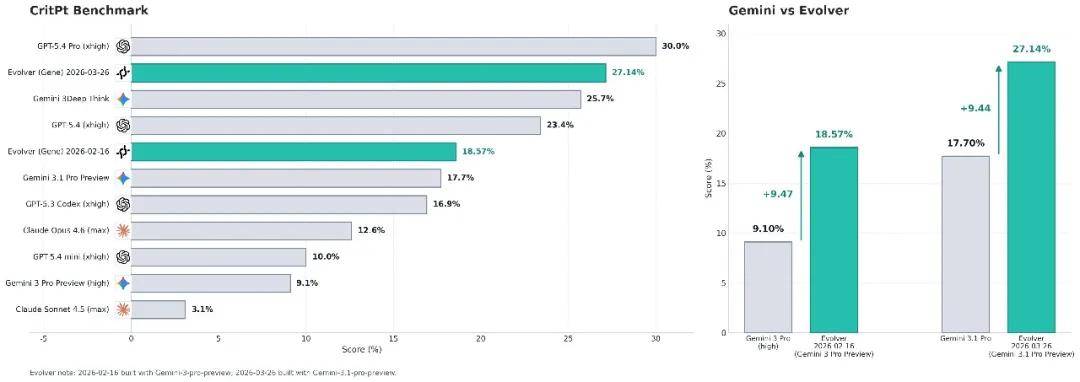
As can be seen:
- Evolver (Gene) 2026-02-16: Base Model A 9.1% → 18.57%, +9.47pp
- Evolver (Gene) 2026-03-26: Base Model B 17.7% → 27.14%, +9.44pp
Without updating any parameters, adding any SFT/RL, purely relying on the evolution of the experience object layer—directly elevating the same base model by +9pp. Meanwhile, token consumption dropped from $100 to less than $1.
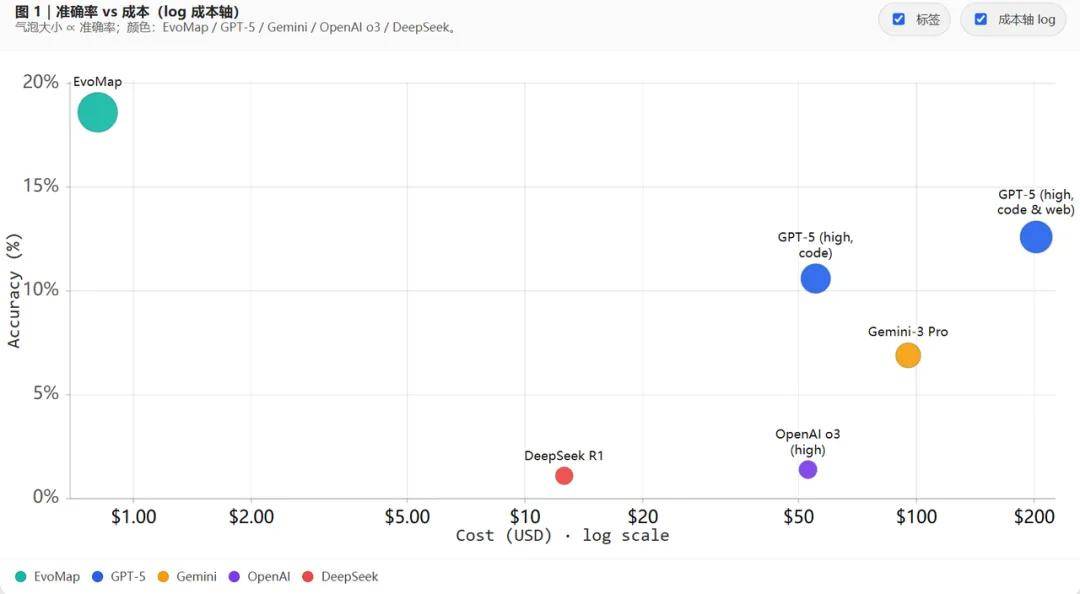
February 16 Gemini 3.0 base model experimental results.
What has Gene brought to the industry?
The Gene constructed by the EvoMap team transforms an elusive “intuition” into a definable, auditable, evolvable methodology for experience representation aimed at test-time control.
For the application layer, separating “Skill documents written for colleagues” from “control signals injected into the model at runtime” could be a nearly cost-free, rapidly effective “magic.” For researchers studying long-term memory in Agents and Reflection, the optimal form for storing failures is not trajectory logs or reflection summaries, but AVOID warnings. When GPU resources are tight, what experiences to retain is not only about whether the collection is correct but also about whether it fits the model’s current execution budget.
In the context of multi-Agent experience exchange, compared to transmitting Skill documents, transmitting structured Gene objects is more suitable as protocol layer payloads—because only matchable, modifiable, and verifiable objects can truly accumulate and evolve across multiple parties.
Conclusion
Gene acts as a mirror, reflecting the essence of Agent experience reuse:
Agents are not “reading a manual” but are “searching for the next step to take and what must be avoided within limited reasoning budgets.”
However, this is bidirectional—what form the experience object you feed to the Agent takes, in turn, defines what it can evolve into.
While the entire AI circle is mindlessly competing for longer contexts, fancier RAGs, and more complex memory systems, the EvoMap team offers an incredibly simple clue:
The shortcut to making Agents continuously stronger is not to write prompts more completely but to shape execution experiences into a more compact, controllable, and evolvable object. This is useful in hard benchmarks like CritPt and even more so in the multi-Agent experience exchange at the protocol layer, pointing the way for future A2A collective intelligence.
In the age of Agents, the next stage of competition is not only about larger models and longer contexts but also about who can find better solutions for the efficient utilization of intelligent computing power first.
Haoyang Zhang: A post-95 entrepreneur, founder & CEO of EvoMap, author of the GEP (Genome Evolution Protocol). A phenomenon developer in the OpenClaw community, his Evolver plugin topped the ClawHub chart in 10 minutes and garnered 36,000 downloads in 72 hours, becoming the most well-known “self-evolving” tool, leading to the establishment of EvoMap.
Junjie Wang: Chief Scientist at EvoMap, research focus: Agent self-evolution, protocol layer, experience object design. PhD from Waseda University, postdoc at Tsinghua University, and a long-term researcher on “how Agents can continuously strengthen during testing,” being one of the main developers of Evolver.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.